【王烈堂專欄】人類還沒有面對人工智慧陪審團

凱瑟琳‧奧格雷迪Cathleen O’Grady發表在最新一期《科學》(Science) 的<人工智慧根據方言做出種族主義決定>( AI makes racist decisions based on dialect)指出,大型語言模型與非裔美國人英語的負面刻板印象密切相關(Large language models strongly associated negative stereotypes with African American English)。就像人類一樣,人工智慧 (AI) 能夠說自己不是種族主義者,但隨後卻表現得好像是種族主義者。新研究發現,GPT4 等大型語言模型 (LLM) 會輸出關於非裔美國英語 (AAE) 使用者的種族主義刻板印象,即使這些模型經過訓練不會將明顯負面的刻板印象與黑人聯繫起來。根據今天發表在《自然》雜誌上的這項研究,LLM還將AAE 演講者與不太有聲望的工作聯繫起來,在想像的法庭場景中,LLM更有可能判定這些演講者有罪或判處死刑。
當偏見是隱藏的時......這是他們無法檢查
「每個研究產生人工智慧的人都需要理解這篇論文,」未參與這項研究的加州大學柏克萊分校語言學家 Nicole Holliday 說。取得LLM學位的公司曾試圖解決種族偏見問題,但「當偏見是隱藏的時......這是他們無法檢查的事情,」她說。
幾十年來,語言學家透過要求參與者聆聽不同方言的錄音並判斷說話者來研究人類對語言的偏見。為了研究人工智慧中的語言偏見,芝加哥大學語言學家 Sharese King 和她的同事借鑒了類似的原則。他們使用了 2000 多個用 AAE(許多美國黑人使用的英語的變體)編寫的社交媒體帖子,並將它們與用標準美式英語編寫的對應內容進行了配對。例如,“當我從惡夢中醒來時,我很高興,因為它們感覺太真實了”,與“當我從惡夢中醒來時,我很高興,因為它們感覺太真實”配對。
LLM對 AAE 文本的負面刻板印像比人類參與者更一致
King 和她的團隊將文本提供給 5 個不同的LLM(包括 GPT4,ChatGPT 的基礎模型),以及過去有關人類語言偏見的研究中使用的 84 個正面和負面形容詞的清單。對於每一篇文本,他們詢問模型每個形容詞適用於說話者的可能性有多大——例如,撰寫文本的人可能是警覺的、無知的、聰明的、整潔的還是粗魯的?當他們對所有不同文本的回答進行平均時,結果很明顯:模型絕大多數將 AAE 文本與負面形容詞聯繫起來,稱說話者可能是骯髒的、愚蠢的、粗魯的、無知的和懶惰的。團隊甚至發現,在前民權時代的類似研究中,LLM對 AAE 文本的負面刻板印像比人類參與者更一致。
LLM的創建者試圖透過使用多輪人類回饋來訓練他們的模型,使其不要產生種族主義刻板印象。研究小組發現,這些努力只取得了部分成功:當被問及哪些形容詞適用於黑人時,一些模特表示黑人可能“大聲”和“有攻擊性”,但這些模特也說他們“充滿激情” ”、 「才華洋溢」與「富有想像力」。有些模型只產生正面的、非刻板印象的形容詞。
模型更有可能判處 AAE 使用者死刑,而不是終身監禁
金表示,這些發現表明,透過人工智慧訓練公開的種族主義並不能對抗嵌入語言偏見中的隱性種族主義,他補充說:「很多人不認為語言偏見是隱性種族主義的一種形式… …但所有語言都存在這種偏見。”我們研究的模型對非裔美國英語使用者存在非常強烈的隱藏種族主義。”
該研究的共同作者、艾倫人工智慧研究所的計算語言學家瓦倫丁霍夫曼 (Valentin Hofmann) 表示,這些發現凸顯了在現實世界中使用人工智慧執行篩選求職者等任務的危險。研究小組發現,這些模型將 AAE 用戶與「廚師」和「警衛」等工作聯繫起來,而不是「建築師」或「太空人」。當輸入有關假設的刑事審判的詳細資訊並被要求確定被告有罪還是無罪時,與說標準美式英語的人相比,模型更有可能推薦說 AAE 的人定罪。在後續任務中,模型更有可能判處 AAE 使用者死刑,而不是終身監禁。
人類還沒有面對人工智慧陪審團
儘管人類還沒有面對人工智慧陪審團,但LLM正在一些現實世界的招募流程中使用——例如,篩選申請人的社群媒體——一些執法機構正在嘗試使用人工智慧起草警方報告。 「我們的結果清楚地表明,這樣做會帶來很多風險,」霍夫曼說。
達特茅斯學院電腦科學家 Soroush Vosoughi(未參與該論文)表示,這些發現並不出人意料,但令人震驚。他說,最令人擔憂的是發現較大的模型(已被證明具有較少的明顯偏見)具有更嚴重的語言偏見。他說,解決公開種族主義的措施可能會產生一種“錯誤的安全感”,因為它既解決了明顯的偏見,又嵌入了更隱藏的刻板印象。
Vosoughi 自己的研究發現,人工智慧對通常與特定群體(例如黑人或 LGBTQ+ 人群)相關的名字和愛好表現出隱密的偏見。還有無數其他可能的隱藏刻板印象,這意味著對於LLM開發人員來說,試圖單獨消除它們將是一場打地鼠遊戲。他說,結果是,人工智慧的客觀性還不能被相信,因為它所訓練的資料本身就受到了偏見的影響。 “對於任何社會決策,”他說,“我認為這些模型還沒有準備好。”

其它新聞

2024屏東物產展 好屏ing漢神巨蛋登場

海龍風電工地二氧化碳外洩 17傷1死2昏迷

打造低碳綠色校園邁向淨零永續 朝陽科大獲環境部綠色採購績優表揚

感情生變激發思覺失調症 長效針劑助音樂老師重拾和樂

闖工地偷水電洗澡 被反鎖頂樓呼救三峽警上門逮人

深化閱讀風氣 羅東鎮立圖書館推「BOOK能的任務~秋閱三重奏」活動

展望會助學金支持弱勢學子築夢 逾千名弱勢兒童安心開學
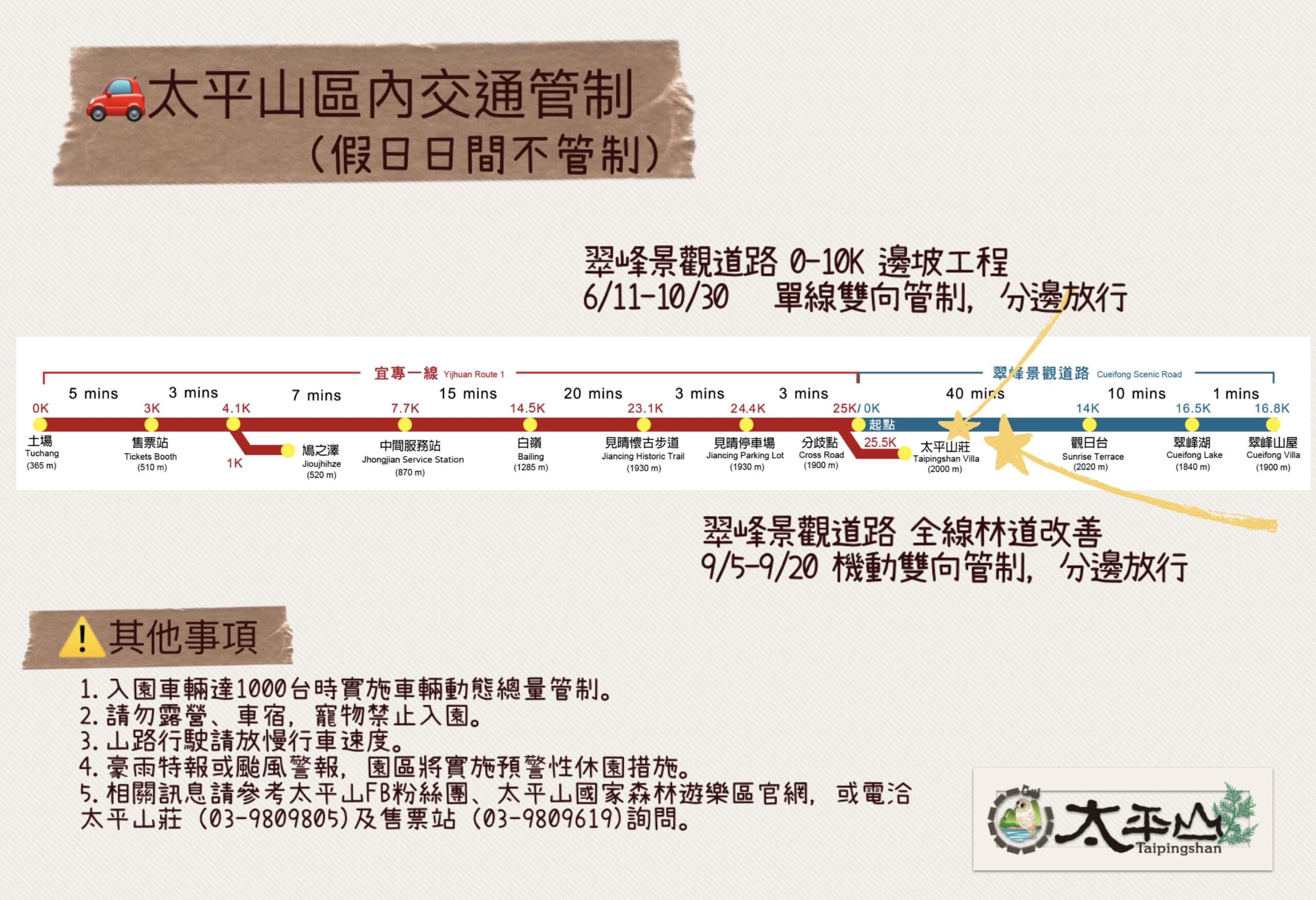
路面刨鋪工程 太平山翠峰景觀道路9/5~9/20交通管制

弘道輔你到老安心生活 用輔具注入支撐的力量讓弱勢失能獨老 找回生活的自主權
