鼎科技/人形機器人聽聲辨位 還給你臉色看(蕭毅豪)

獨家報導 蕭毅豪/評論
當你問吧檯的Tesla Optimus人形機器人,給我一杯飲料吧!
但重點是…桌上哪一個是空杯?又剩幾杯?視覺障礙很多,人形機器人的視覺功能需要「看清楚形狀」哪個空杯子可被盛滿。
當你聽到電話響了,跟人形機器人說:請幫忙Sasha接聽電話。
但重點是…辦公室裡有十幾支分機,人形機器人聲覺功能需要「聽清楚方位」是哪一支分幾響起來了。
Tesla Robotaxi自駕車發表外的一大亮點:Optimus人形機器人
以上的第一個視覺橋段,在11日的Tesla活動名為“We,Robot”被上演,同時也是對Isaac Asimov的《I,Robot》科幻小說集的致敬,剛好我也有這本書,”I,Robot”也被拍成電影在2004年上映,台灣譯為「機械公敵」由Will Smith主演,我個人就觀賞過5次之多。主要是體會電影台詞裡說的一句話:「He suggested that robots might naturally evolve.」,就因為AI 演算法的某個程式小片段可以讓人形機器人能自我演進,真的很神奇。
“We,Robot”間接也呼應了Elon Musk的遠見,就是希望Tesla應該被視為一家AI Robot公司,而不是一家電動車製造商,因為無論車載、人形機器人、衛星、任何電腦內,都有人工智慧的軟體機器人在幫助人類完成某些任務。
這次“We,Robot”的活動中,Tesla Optimus人形機器人Gen III在活動會場中擔任了牛仔調酒師(Bartender in a cowboy hat)是一大亮點,主要是它可以跟周邊的參與者互動良好,但大家發現一個問題:
那就是在參與者人類與面無表情的Optimus人形機器人自然語言對話當中,Tesla Optimus人形機器人偶爾仍需要等待AI資料中心傳來的雲端回答,這一等待瞬間,會讓周邊參與者隨之等待而產生尷尬,同時參與者也會覺得Optimus人形機器人暫時不動是怎麼了?壞掉了嗎?
即便回應很即時,但沒有表情類似生物的一個人形機器人,跟你對話終究怪怪的…
我們鼎科技一篇文章:
AI走出虛擬,真貌迎向你5-3
提到2027年後的次世代人形機器人的臉部表情在對應人類時,是至關重要的訊息傳達以及指令回饋。未來的AI人形機器人如果要走入像是商務領域、餐飲領域、醫療領域等等這些服務類的應用,有表情回饋的人形機器人才是被服務的人類所需要的。
才不至於像這次活動中Tesla Optimus人形機器人的面無表情,很難讓參與者知道他下一步的對應是什麼,讓尷尬因而產生。
人形機器人的感知覺器官
人形機器人除了機械結構的支架骨骼和關節外,為了扮演好12種表情以上的生成,五種感知的「視覺」、聽覺、觸覺、味覺、和嗅覺的感測器也極為關鍵,這其中視覺最為重要。
儘管台灣是尖端感測器供應的供應大國,但仍舊需要AI模型來輔助建立給人形機器人做各種感知的判斷便是,機器人五感會各自有自己的AI模型來負責。
由於篇幅的關係,本文先介紹AI視覺系統(AI Vision System)與AI聽覺系統(AI Hearing System)讓大家了解,這中間nVIDIA、和Meta扮演了這兩種系統內相當重要的AI感知模型角色。
人形機器人臉部的內、外部感測器
感測器對於需要應付多重任務的人形機器人是感知世界的重要關鍵零組件,台灣未來有機會將精準的MEMS晶片提供給Tesla、Figure AI服務。
跟人類不同的是,人形機器人感測器不但用來了解外面的世界,同時也需要感測人形機器人的內部運作情況。人形機器人的感應裝置十分多元化。簡單來說可分為內部感測器(Internal Sensor)和外部感測器(External Sensor)。
內部常有:
關節角度感測器(Joint-angle sensor)、六軸力度感測器(6-axis force sensor)、加速度感測器(Acceleration sensor)和陀螺儀(Gyroscope)等等。關節角度感測器用來辨認關節在各個時刻的位置。六軸力度感測器安裝在手腕和腳腕,手腕的感應器用來感應手部的移動方向和力度,腿部的感測器配合攝影機拍攝得來的影像,決定人形機器人腳步的位置和方向。加速度感測器及迴轉儀用來感應身軀傾斜和加速的程度以平衡身體。
外部就是:
探測人形機器人所身處環境的狀況。外部感測器又可分為接觸式感測器 (Contact sensor)、近距感測器(Proximity sensor)和遠距感測器(Far away sensor)。
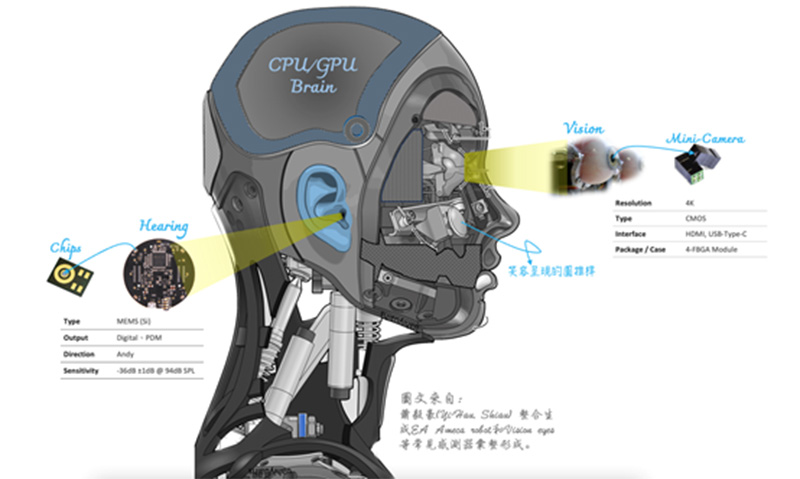
其中遠距感測器便是人類也都擁有的視覺和聽覺。如上圖一,人形機器人的視覺系統內最重要的感測元件,便是藏身眼球內的3D/2D攝影鏡頭(常用CMOS或CCD晶片),將收集得來的影像經過取樣及量化,轉換為電子訊號,然後交由GPU Brain進行前期的處理、分段、描述、辨識、解譯等數位影像處理工序。
有了視覺系統,這時候就得加入nVIDIA的AI感知模型的學習與推理,最常見的就是nVIDIA Isaac Sim構建的應用程式,也針對人形機器人進行了最佳化學習,並可以訓練所有型別的人形機器人視覺感應實現。
Isaac Sim支援多種感測器型別,從基於視覺的感測器到雷達和鐳射雷達,包括基於物理的感測器,如接觸和IMU(慣性測量單元)。也還可以在Isaac Sim中構建自己的自定義感測器,當然像上述的基本型的3D/2D攝影鏡頭也是被當作感知訓練的影像來源。
當視覺系統有了AI去處理影像得到感知後,便能依照既有的AI模型影像,精確判別哪一個是空杯或是滿杯,人形機器人的手部才能移動到正確的杯子進行拿取,並再移動到拉霸飲料機進行飲料填充動作。
AI聲學模型的收音來源是陣列式麥克風
例如Meta之前2018年研究的SoundSpaces是一種AI聲學模型。很適合搭配在人形機器人的耳朵裡的聲音感測晶片中。
此平台,研究人員可以在具有高度逼真的聲學的3D環境中,來訓練AI。這開闢了導航人形機器人到發聲目標、從回聲定位中學習或使用多模態感測器(例如陣列麥克風)來進行探索。任何物件代表的聲音不僅能讓人形機器人產生更快的訓練和更準確的推理導航,也使AI指揮人形機器人能夠從遠處自行發現目標。Meta的AI聲學模型研究使AI能夠學習和推理如何導航到有發出聲音的電話是哪一隻。
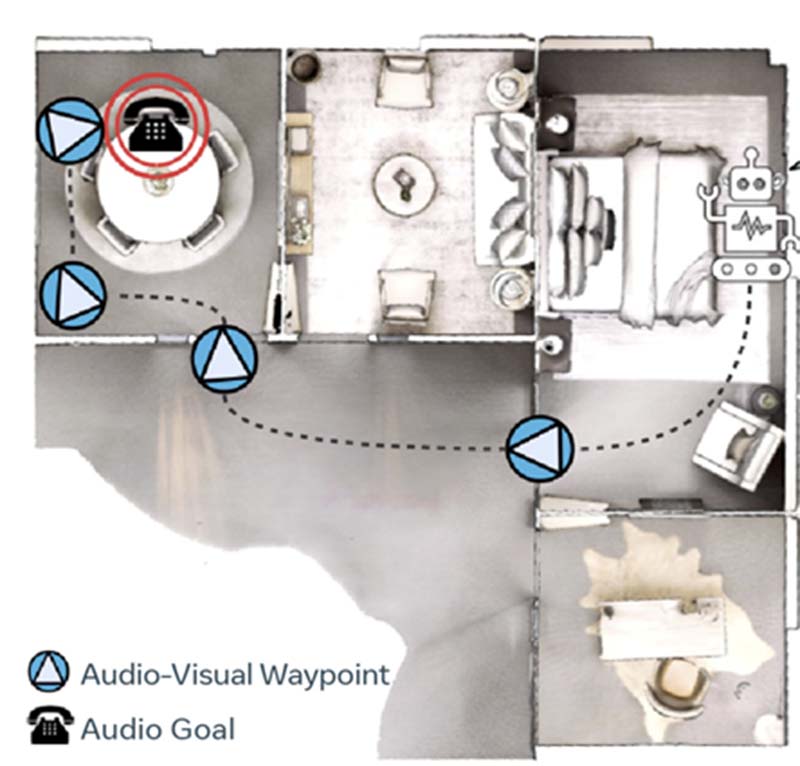
如上圖二,是Meta的SoundSpace模擬,對於放置在任何位置的音訊源,AI會注意到它。當聲源播放時,人形機器人在不同位置接收的聲音是如何變化的,以及環境中的3D結構物件如何影響聲音反射與傳播,人形機器人就能判斷正在響的電話位置,且有別於傳統的機器人導航系統必須應對特定的點。
本文簡要說明了人形機器人的「視覺」、和「聽覺」,另一方面也提及了感測器,至於感測器的供應鏈和他們的規格,將會在另外一篇繼續闡述。
最後,除了感測器在過去的幾十年裡應用在人形機器人身上做研究外,聲學系統內的聲波和視覺系統內的光波,對微觀和中觀物體施加非接觸力的應用也變得相當重要,不同的物理原理支配著聲音能量和光子能量,未來也能應用於多樣化的生物醫學應用,這就如同nVIDIA CEO黃仁勳提到的,未來AI最直得研究的是醫療、醫學。
我也預期醫學上常用的光聲學(Photoacoustics)技術,也會轉移到人形機器人上,來幫助人類在醫療上的進步。關於人形機器人在醫療上的進展,我將在下期進行解說。
註釋:光聲學內有一種聲光效應,指的是當光波以週期性的照射人體時,某些物質會發出聲音,其聲音的頻率和強度則受到光種的影響其在生物醫學影像建立中有多重運用,,目前多應用於活體血管成像。
自己的國家自己救……《民意大聲公》歡迎投稿建言,以1000字為限,惟無稿酬,來稿請註明《民意大聲公》並附真實姓名及聯絡方式;另《名家專欄》徵能拚流量好手,字數不限以篇計酬;本媒體有准駁權利,來稿請寄:[email protected]
更多《獨家報導》
相關新聞
網路盛傳雞角刺茶可根治糖尿病 是真的嗎?

只要不在毛小孩面前吸菸 菸就不會危害毛小孩?

酒駕累犯公布30名 酒駕拒測累犯罰36萬元

表揚食農教育推手 共創健康永續飲食環境

九旬老翁回診走失 暖警助團圓

白晝之夜 11月開啟「夜行動物派對」模式

透過食農教育創意遊程推廣在地農糧 中衛中心精選二條國產雜糧農遊路線農村旅遊趣

《今周刊》2024永續城市大調查 黃敏惠連三年獲最佳首長信任獎

響應2050淨零碳排 中醫大附醫簽署醫院永續發展倡議書
